Karpathy의 LLM Wiki 완전 정복: 초보자도 따라 할 수 있는 개념 정리
"Obsidian은 IDE, LLM은 프로그래머, Wiki는 코드베이스다." — Andrej Karpathy
요즘 개발자 커뮤니티에서 가장 뜨거운 화두 중 하나가 바로 Karpathy의 LLM Wiki 입니다. 2026년 4월 4일 Andrej Karpathy(전 OpenAI 공동창업자, 전 Tesla AI 디렉터)가 GitHub Gist에 올린 단 하나의 markdown 파일이 발표 2주 만에 별 5,000개, 포크 4,400개를 돌파하며 AI 개발자 커뮤니티의 지식 관리 방식을 뒤흔들고 있습니다.
이 글에서는 LLM Wiki가 정확히 무엇인지, 왜 사람들이 열광하는지, 어떻게 따라 만들 수 있는지, 그리고 비슷한 개념들은 무엇이 있는지 초보자도 이해할 수 있도록 정리했습니다.

1. 한 줄 요약: LLM Wiki란 무엇인가?
LLM Wiki는 "AI가 직접 만들고 유지보수하는 나만의 위키피디아"입니다.
조금 더 풀어쓰면 이렇습니다.
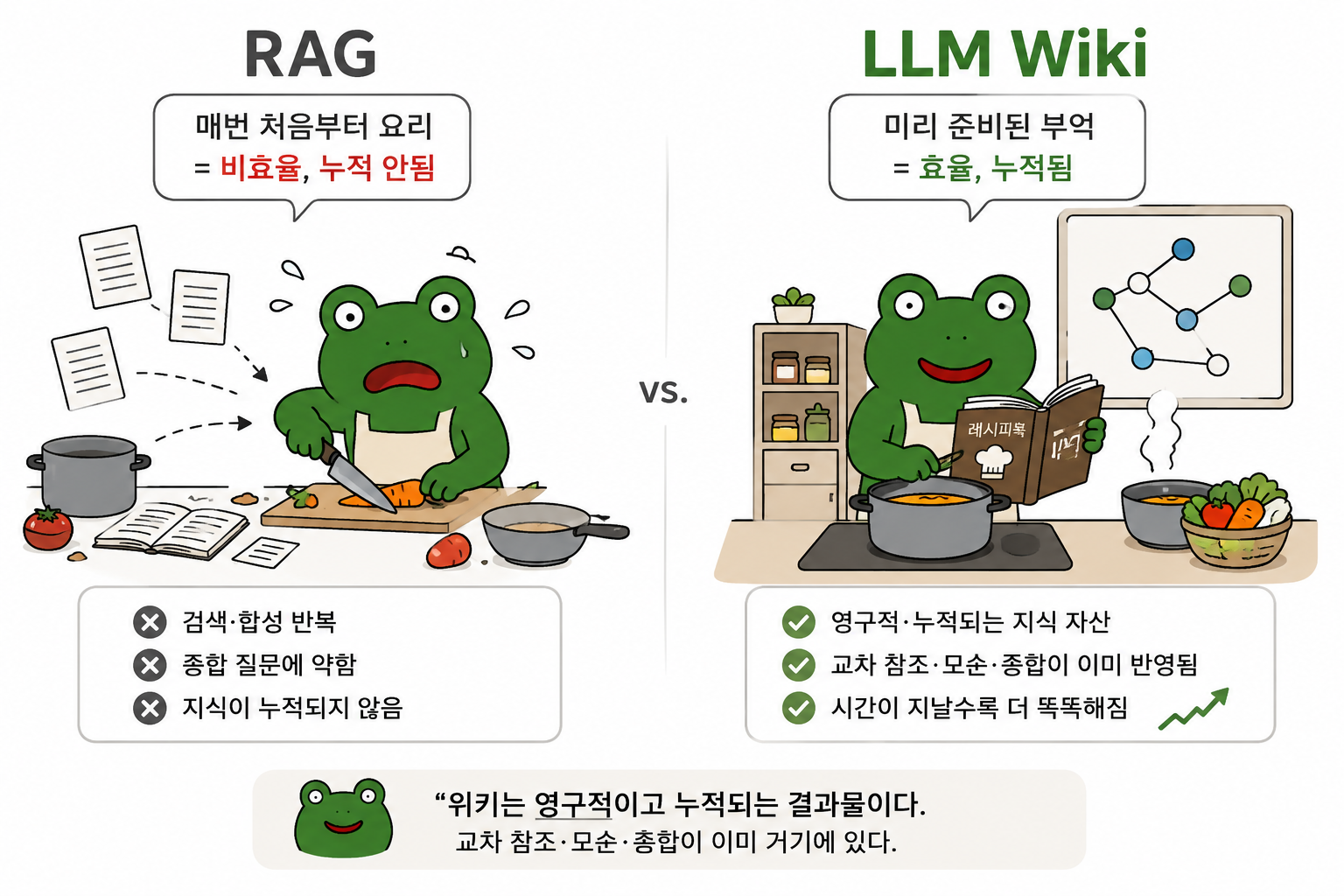
기존에는 우리가 ChatGPT나 NotebookLM에 PDF를 던져두고 질문할 때마다, AI가 매번 처음부터 문서를 읽고 관련 부분을 찾아 답을 만들어냈습니다. 이를 RAG(Retrieval-Augmented Generation)라고 부릅니다. 문제는 매 질문마다 AI가 똑같은 일을 반복한다는 점입니다. 어떤 지식도 누적되지 않습니다.
Karpathy가 제안한 LLM Wiki는 발상을 뒤집습니다. 질문할 때 검색하는 게 아니라, 자료를 받을 때 미리 정리해두는 방식입니다. 새로운 문서를 추가하면 LLM이 그 자리에서 핵심을 추출하고, 기존 페이지를 업데이트하고, 모순되는 내용을 표시하고, 관련 개념끼리 링크를 만듭니다. 그렇게 만들어진 위키는 시간이 지날수록 점점 더 똑똑해지는 영구적인 자산이 됩니다.
2. 시스템의 핵심 3가지 기능
LLM Wiki는 본질적으로 세 가지 역할이 맞물려 돌아가는 시스템입니다. 이 셋을 제대로 이해하면 LLM Wiki를 다 이해한 것입니다.
기능 1: Wiki — "지식이 누적되는 영구 저장소"
위키는 이 시스템의 결과물이자 자산입니다. 단순한 노트 모음이 아니라, 시간이 지날수록 점점 더 똑똑해지는 살아있는 지식 그래프입니다.
위키의 본질은 Markdown 파일들의 폴더입니다. 화려한 데이터베이스도, 벡터 임베딩도 필요 없습니다. 그냥 평범한 텍스트 파일 수십 개에서 수천 개가 폴더 구조 안에 들어 있을 뿐입니다. 이 단순함이 바로 강력함의 비결입니다. 어떤 도구로든 읽을 수 있고, GitHub에 그대로 백업할 수 있고, 10년 뒤에도 열어볼 수 있습니다.
위키 안에는 보통 다음과 같은 페이지 타입이 들어갑니다. Entity 페이지(인물, 회사, 도구처럼 세상의 구체적 대상), Concept 페이지(추상적 개념, 이론, 방법론), Source 페이지(원본 자료의 구조화된 요약), Topic 페이지(여러 개념을 묶는 상위 주제 지도). 각 페이지는 다른 페이지를 [[wikilink]] 형식으로 참조하며, 이 링크들이 모여 의미 그래프를 형성합니다.
가장 중요한 특성은 누적성(compounding) 입니다. 첫 자료를 넣을 때는 페이지 5개가 생기지만, 50번째 자료를 넣을 때는 기존 50개 페이지 중 10-15개가 동시에 업데이트되면서 새 연결이 생깁니다. 페이지 수가 산술급수적으로 늘어나는 동안, 의미 있는 연결의 수는 기하급수적으로 늘어납니다. 50번째 자료가 1번째 자료보다 위키에 훨씬 더 많은 가치를 더합니다.
위키 안의 모든 페이지는 사람이 직접 읽을 수 있는 markdown입니다. AI 없이도 검색하고 탐색할 수 있다는 뜻입니다. 이게 벡터 DB 기반 RAG와의 결정적 차이입니다.
기능 2: AI Agent — "위키의 사서이자 탐색가"
AI는 이 시스템의 엔진입니다. 두 가지 모드로 동작합니다.
컴파일러 모드에서 AI는 새 자료가 들어오면 다음 작업을 자동으로 수행합니다. 핵심 정보 추출, 기존 페이지와의 비교, 관련 페이지 업데이트, 새 entity 페이지 생성, 모순 표시([!contradiction] 콜아웃), 교차 참조 링크 생성, 인덱스 갱신. 이 모든 일이 한 번의 ingest 명령으로 5-15개 페이지에 동시에 일어납니다. 인간이 가장 싫어하는 부기 업무 전체를 AI가 가져갑니다.
탐색가 모드에서 AI는 질문에 답합니다. 중요한 차이는 AI가 raw 자료(원본 PDF, 웹 클립)를 다시 읽지 않는다는 점입니다. 대신 이미 잘 정리된 위키 페이지들을 읽고, wikilink를 따라가면서 답을 합성합니다. 그 결과 답변이 빠르고, 정확하고, 항상 출처가 명시되며([[wikilink]] 인용), 종합 질문에 강합니다. "내가 읽은 모든 자료에서 X 주제는 어떻게 진화했나?" 같은 질문이 가능해집니다.
추가로 AI는 정기적인 건강 검진(health check) 도 수행합니다. 깨진 링크, 고립된 페이지, 모순 표시, 콘텐츠 갭을 자동으로 찾아내고 수정 제안을 합니다.
여기서 중요한 점: 이 AI는 Claude만이 아닙니다. Gemini, Codex, OpenCode 등 어떤 에이전트형 코딩 도구든 사용할 수 있습니다. 이 부분은 5장에서 자세히 다룹니다.
기능 3: Obsidian — "사람을 위한 시각화 인터페이스"
Obsidian은 이 시스템의 창문입니다. 위키가 만들어진 markdown 파일들을 사람이 직관적으로 보고, 탐색하고, 수정할 수 있게 해줍니다.
Obsidian이 LLM Wiki에 표준 인터페이스가 된 이유는 세 가지 핵심 기능 때문입니다.
Graph View는 위키를 시각적인 지식 그래프로 보여줍니다. 각 페이지가 노드, 각 wikilink가 엣지가 됩니다. 자료를 추가할 때마다 이 그래프가 점점 풍성해지는 모습을 보는 것 자체가 동기 부여가 됩니다. 색상 필터로 entity는 파란색, concept은 초록색, source는 흰색으로 구분하면 어떤 영역에 자료가 부족한지 한눈에 보입니다.
Wikilink와 Backlink는 양방향 연결을 자동으로 관리합니다. A 페이지에서 [[B]]라고 쓰면 B 페이지에는 자동으로 "A에서 나를 참조함"이 표시됩니다. AI가 만든 모든 링크가 양방향으로 작동하므로, 어떤 페이지에서 시작해도 관련된 모든 맥락에 도달할 수 있습니다.
Local-First 파일 시스템은 vault가 그냥 평범한 폴더라는 사실입니다. 클라우드 종속도 없고, 독점 포맷도 없습니다. 이 폴더를 Claude Code, Cursor, OpenCode 같은 외부 AI 도구가 자유롭게 읽고 쓸 수 있다는 게 핵심입니다. Obsidian이 IDE 역할을 하고, AI가 그 안의 파일을 편집하는 프로그래머 역할을 한다는 Karpathy의 비유가 여기서 나옵니다.
추가로 plugin 생태계도 강력합니다. Web Clipper로 어떤 웹페이지든 markdown으로 저장하고, Canvas로 시각적 보드를 만들고, Bases로 데이터베이스 뷰를 만들 수 있습니다.
💡 세 기능의 관계: Wiki는 무엇이 만들어지는가, AI는 어떻게 만들어지는가, Obsidian은 사람이 어떻게 보는가를 담당합니다. 셋 중 하나라도 빠지면 시스템이 무너집니다. Wiki만 있으면 유지보수가 안 되고, AI만 있으면 결과가 흩어지고, Obsidian만 있으면 다시 수동 노트 시스템입니다.
3. 왜 이 개념이 혁신적인가?
기존 RAG의 한계
전통적인 RAG 방식을 요리에 비유하면 이렇습니다. 배가 고플 때마다 매번 장을 보고, 재료를 손질하고, 처음부터 요리를 만드는 셈입니다. 빠르고 편리해 보이지만 비효율적이고, 어떤 노하우도 쌓이지 않습니다.
구체적으로 RAG는 다음과 같은 약점을 가집니다.
첫째, 매 쿼리마다 동일한 검색-합성 과정을 반복합니다.
둘째, 5개 문서를 종합해야 답할 수 있는 미묘한 질문에는 답하기 어렵습니다.
셋째, 지식이 누적되지 않아서 50번째 질문이 1번째 질문보다 더 똑똑해지지 않습니다.
LLM Wiki의 접근
반면 LLM Wiki는 미리 모든 재료를 손질해 잘 정리된 부엌을 만드는 방식입니다. 한번 만들어두면 평생 활용할 수 있는 레시피 북이 됩니다.
핵심 차이점을 정리하면 이렇습니다. RAG는 stateless(상태가 없음)이고, LLM Wiki는 stateful(상태가 누적됨)입니다. RAG는 채팅이 끝나면 사라지는 일회성 답변을 만들고, LLM Wiki는 영구적으로 남아 시간이 지날수록 가치가 증가하는 지식 자산을 만듭니다.
Karpathy 본인의 말을 빌리면, "위키는 영구적이고 누적되는 결과물이다. 교차 참조는 이미 거기 있다. 모순은 이미 표시되어 있다. 종합은 이미 당신이 읽은 모든 것을 반영한다"입니다.
4. LLM Wiki의 폴더 구조
3-Layer 아키텍처
LLM Wiki는 보통 세 개의 층으로 구성됩니다.
첫 번째는 Raw 레이어입니다. 원본 자료를 그대로 보관하는 곳으로, PDF 논문, 웹 클리핑, 회의 노트 등이 들어갑니다. 절대 수정되지 않는 불변의 입력 데이터입니다.
두 번째는 Wiki 레이어입니다. LLM이 raw 자료를 읽고 만든 구조화된 markdown 페이지들이 모이는 곳입니다.
세 번째는 Schema 레이어입니다. CLAUDE.md(또는 AGENTS.md, GEMINI.md 등 사용 도구에 따라)라는 파일에 LLM이 따라야 할 규칙, 페이지 템플릿, 작업 흐름이 정의됩니다. 이 파일이 일반 챗봇이었던 AI를 규율 잡힌 위키 관리자로 바꿉니다.
표준 폴더 구조
my-wiki/
├── CLAUDE.md # 위키 운영 규칙 (스키마)
├── raw/ # 원본 자료 (불변)
│ ├── papers/
│ ├── articles/
│ └── notes/
├── wiki/ # LLM이 만든 구조화된 페이지
│ ├── concepts/ # 추상 개념
│ ├── people/ # 인물
│ ├── topics/ # 주제 지도
│ └── sources/ # 자료별 요약
├── index.md # 전체 콘텐츠 카탈로그
└── log.md # 시간순 작업 로그
5. 🔧 어떤 AI 도구를 쓸까? — 유료/무료 옵션 총정리
LLM Wiki의 가장 큰 매력 중 하나는 특정 회사에 종속되지 않는다는 점입니다. Karpathy의 gist는 "Claude Code, OpenAI Codex, OpenCode 등 어떤 에이전트와도 함께 쓸 수 있다"고 명시하고 있습니다. 자기 예산과 취향에 맞는 도구를 고르면 됩니다.
🟢 완전 무료로 시작할 수 있는 옵션
Gemini CLI (Google, 오픈소스, 가장 관대한 무료 티어): 하루 1,000건의 무료 요청, Gemini 2.5 Pro/Flash 자동 라우팅, 100만 토큰의 거대한 컨텍스트 윈도우를 무료로 제공합니다. "한 푼도 쓰기 싫다"면 1순위 추천입니다. 다만 가끔 안전 필터가 과하게 작동해 거부하는 경우가 있고, MCP 같은 고급 기능은 설정이 까다로울 수 있습니다.
OpenCode (SST 팀, 오픈소스, GitHub 별 14만 7천 개): Claude Code의 가장 강력한 오픈소스 대안입니다. 75개 이상의 LLM 제공자를 지원해서 Claude, GPT, Gemini, Grok, 또는 Ollama로 로컬 모델까지 자유롭게 사용 가능합니다. GitHub Copilot이나 ChatGPT Plus 구독 계정으로도 인증할 수 있어, 기존 구독을 활용할 수 있습니다. 도구 자체는 무료이고, API 비용만 지불하면 됩니다(또는 로컬 모델을 쓰면 0원).
Aider (오픈소스, GitHub 별 2만 1천 개): "AI 페어 프로그래밍" 컨셉의 가장 검증된 도구입니다. 100개 이상의 모델 지원, 자동 git 커밋, repository map 기능이 강력합니다. 토큰 효율성이 가장 좋아서 같은 작업에 다른 도구의 절반 토큰만 씁니다. 도구는 무료, BYOK(Bring Your Own Key) 방식.
Goose (Block, Apache 2.0 오픈소스): MCP 통합이 가장 강력한 도구입니다. 데스크톱 앱과 CLI를 모두 제공하고, 자율 워크플로우에 강합니다. 도구 무료, 모델 비용은 별도.
Cline / Continue (VS Code 확장, 오픈소스): IDE 안에서 작업하는 게 편하다면 이쪽이 좋습니다. 둘 다 BYOK 방식으로 어떤 모델이든 연결 가능합니다. Cline에는 무료 Kimi K2.5 모델이 번들되어 있어 0원으로도 쓸 수 있습니다.
Ollama + 로컬 모델 (완전 오프라인): 인터넷 없이 자신의 컴퓨터에서 Llama 3.3, Qwen 2.5, DeepSeek 등을 돌려 OpenCode/Aider/Cline에 연결합니다. API 비용 0원, 데이터 100% 로컬. 다만 16GB 이상 RAM과 가능하면 GPU가 필요합니다.
🟡 유료지만 가성비 좋은 옵션
ChatGPT Plus + Codex CLI ($20/월): GPT-5 시리즈 기반의 OpenAI 공식 코딩 에이전트입니다. ChatGPT 구독에 포함되어 별도 결제가 없습니다. 40만 토큰 입력 컨텍스트, 멀티모달 입력 지원, 클라우드 작업 위임 기능이 강점입니다. 이미 ChatGPT Plus 사용자라면 추가 비용 0원입니다.
GitHub Copilot CLI ($10/월부터): Claude, GPT, Gemini를 한 구독으로 쓸 수 있습니다. Plan mode와 PR 자동화가 강점이지만 무료 티어가 월 50건으로 빡빡합니다. 이미 Copilot 쓰는 개발자에게 추천.
Cursor ($20/월): IDE형 도구지만 LLM Wiki에도 사용할 수 있습니다. 비주얼 diff와 멀티모델 지원, 자동완성이 가장 부드럽습니다.
🔴 프리미엄 옵션
Claude Code (Anthropic, $20-200/월): Karpathy의 원본 gist에서 1차로 추천된 도구이며 OmegaWiki, claude-obsidian 같은 주요 구현체들의 기본 환경입니다. Claude Opus 4.6/4.7과 Sonnet 4.6에 최적화되어 있고, Skills 시스템으로 Obsidian 통합이 가장 매끄럽습니다. 단점은 Anthropic 모델만 쓸 수 있다는 점과 사용량 따라 비용이 빠르게 늘 수 있다는 점입니다. Pro($20/월) 플랜으로도 가벼운 LLM Wiki 운영은 충분합니다.
Warp 2.0 ($15-40/월): 터미널 자체를 대체하는 GPU 가속 도구입니다. Claude Code, Codex, Gemini CLI를 한 인터페이스 안에서 동시에 돌릴 수 있습니다. 무료 티어는 월 150건, Turbo는 $40/월.
어떻게 선택할까?
목적별로 추천을 정리하면 다음과 같습니다.
0원으로 시작: Gemini CLI 또는 OpenCode + Ollama 가성비 최고: ChatGPT Plus 사용자 → Codex CLI / 그 외 → OpenCode + DeepSeek API (월 5-15달러) 프라이버시 최우선: OpenCode + Ollama로 100% 로컬 최고 품질: Claude Code (Karpathy의 원본 워크플로우) 기존 도구 재활용: GitHub Copilot 사용자 → OpenCode (Copilot 인증), ChatGPT Plus 사용자 → Codex CLI
💡 중요: 위키는 그냥 markdown 폴더이기 때문에, 도구를 언제든 갈아탈 수 있습니다. Gemini CLI로 시작했다가 나중에 Claude Code로 옮겨도 위키 자산은 그대로 유지됩니다. CLAUDE.md를 GEMINI.md로 복사하기만 하면 됩니다.
6. 초보자를 위한 단계별 셋업 가이드
Step 1: Obsidian Vault 만들기
먼저 Obsidian을 다운로드합니다(무료). 새로운 vault를 ~/wiki 또는 ~/Documents/llm-wiki 같은 폴더에 만듭니다. Obsidian의 vault는 그냥 markdown 파일이 들어있는 일반 폴더이므로, 외부 AI 도구에서도 자유롭게 접근 가능합니다.
Step 2: AI 도구 설치
위 5장에서 고른 도구를 설치합니다. 모든 도구가 Node.js를 필요로 하므로 먼저 Node.js를 설치하세요. 그다음 예시 명령어들입니다.
# Gemini CLI (무료)
npm install -g @google/gemini-cli
# OpenCode (오픈소스, BYOK)
npm install -g opencode-ai
# Aider (Python)
pip install aider-install && aider-install
# Claude Code (유료)
npm install -g @anthropic-ai/claude-code
Step 3: AI 도구에 Karpathy gist 넘기기
Vault 폴더로 이동해 AI 도구를 실행한 뒤 다음과 같이 프롬프트를 던집니다.
당신은 지금부터 [관심 주제]에 대한 나의 LLM Wiki 에이전트입니다.
아래 첨부된 Karpathy의 LLM Wiki 패턴을 참고하여, 이 vault에
완전한 second brain을 구축해주세요. 다음을 단계별로 안내해주세요:
1. 스키마 파일 생성 (전체 규칙 포함, Claude Code면 CLAUDE.md,
Gemini CLI면 GEMINI.md, OpenCode면 AGENTS.md)
2. raw/, wiki/ 폴더 구조 초기화
3. 페이지 템플릿 생성 (concept, person, source 등)
4. index.md와 log.md 초기화
[여기에 https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f 의 내용 붙여넣기]
Step 4: 핵심 슬래시 명령어 3개
위키를 운영하는 데는 단 3개의 명령어만 있으면 됩니다. AI 도구에게 이 명령어들을 만들어달라고 요청하세요.
/ingest-url <URL or 파일경로>: URL이나 PDF를 던지면 LLM이 자동으로 핵심을 추출하고 5-15개의 위키 페이지를 한 번에 업데이트합니다.
/process-inbox: raw/inbox/에 쌓아둔 짧은 메모와 단상을 자동으로 분류해 적절한 위치에 통합합니다.
/lint-wiki: 위키의 건강 상태를 점검합니다. 깨진 링크, 고립된 페이지, 모순되는 내용, 보강이 필요한 콘텐츠 갭을 찾아냅니다.
Step 5: 첫 자료 넣어보기
준비가 끝났으면 좋아하는 블로그 글이나 논문 PDF를 raw/ 폴더에 넣고 /ingest-url을 실행해봅니다. Obsidian으로 vault를 열고 graph view를 켜면 위키 페이지들이 노드로, 링크들이 엣지로 시각화됩니다. 자료를 더 넣을수록 그래프가 풍성해지는 모습이 직접 보입니다.
7. 실전 운영 팁
작게 시작하세요. Karpathy 본인의 위키도 약 100개 페이지, 40만 단어 규모입니다. 처음부터 거대한 시스템을 만들려고 하지 마세요. 한 가지 관심 주제(예: "강화학습", "투자 철학", "건축 디자인")에 집중한 미니 위키부터 시작하는 게 좋습니다.
Obsidian Web Clipper를 활용하세요. 브라우저 확장으로 어떤 웹페이지든 markdown으로 변환해 raw/ 폴더에 직접 저장할 수 있습니다. 북마크를 누르듯 빠르게 자료를 모을 수 있습니다.
정기적으로 health check를 돌리세요. 일주일에 한 번 정도 /lint-wiki를 실행해 모순과 갭을 정리하면 위키가 썩지 않습니다.
Graph View를 자주 보세요. 어떤 영역이 빈약한지, 어떤 클러스터가 고립되어 있는지 한눈에 보입니다. 이게 다음 자료를 무엇으로 채울지 결정하는 데 도움이 됩니다.
역할이 바뀝니다. 더 이상 당신이 노트를 정리하지 않습니다. 당신은 좋은 자료를 큐레이션하고, 좋은 질문을 던지고, 생각하는 데 집중합니다. LLM이 모든 정리, 링크, 업데이트, 부기 업무를 처리합니다.
8. 비슷한 개념들 — LLM Wiki의 친척들
LLM Wiki는 갑자기 하늘에서 떨어진 아이디어가 아닙니다. 수십 년에 걸친 지식 관리 패러다임의 흐름 위에 서 있습니다. 알아두면 좋은 비슷한 개념들을 정리합니다.
Zettelkasten (체텔카스텐)
독일 사회학자 Niklas Luhmann이 개발한 카드 기반 노트 시스템입니다. 그는 이 방법으로 70권 이상의 책과 수백 편의 논문을 썼습니다. 핵심 원칙은 "atomic note(하나의 노트에는 하나의 아이디어만)"와 "dense linking(촘촘한 상호 연결)"입니다. LLM Wiki와 매우 유사하지만, 결정적 차이는 유지보수의 주체입니다. Zettelkasten은 인간이 직접 링크를 그어야 하는 반면, LLM Wiki는 AI가 대신 해줍니다. 많은 사람들이 Zettelkasten의 이론에는 감동받지만 실천에서 좌절하는 이유가 바로 이 유지보수 부담 때문이었습니다.
Building a Second Brain (BASB)
Tiago Forte가 대중화한 개념으로, "디지털 외장 뇌"를 만들어 단기 기억의 부담을 덜자는 철학입니다. CODE(Capture, Organize, Distill, Express)라는 4단계 워크플로우를 제시합니다. LLM Wiki는 BASB의 "Distill" 단계를 자동화한 AI 시대의 진화형으로 볼 수 있습니다.
Memex (Vannevar Bush, 1945)
거의 80년 전 Vannevar Bush가 "As We May Think"라는 에세이에서 제안한 개념입니다. 모든 책, 기록, 통신을 저장하고 연관 검색으로 탐색할 수 있는 기계를 상상했습니다. 하이퍼텍스트의 시초이자 LLM Wiki의 정신적 조상입니다. 누군가는 "LLM Wiki 덕분에 마침내 Memex가 만들어질 수 있게 됐다. 우리에게 드디어 진짜 일하는 사서가 생겼기 때문이다"라고 평했습니다.
Knowledge Graph (지식 그래프)
엔티티(노드)와 관계(엣지)로 지식을 표현하는 데이터 구조입니다. Google 검색, Wikidata, 의학 정보 시스템 등에서 사용됩니다. LLM Wiki도 본질적으로 markdown 기반의 knowledge graph입니다. 다만 전통적인 knowledge graph가 엄격한 schema와 triple(주어-술어-목적어)을 요구하는 반면, LLM Wiki는 자연어로 유연하게 표현됩니다.
RAG (Retrieval-Augmented Generation)
LLM Wiki의 직접적인 비교 대상입니다. 외부 문서에서 관련 청크를 찾아 LLM의 답변에 참조시키는 방식으로, NotebookLM, ChatGPT 파일 업로드, 대부분의 기업용 챗봇이 이 방식을 사용합니다. 빠른 셋업과 단순한 질문에 강하지만, 지식 누적이 안 된다는 약점이 있습니다.
Agent Memory (에이전트 메모리)
AI 에이전트가 세션 간에 기억을 유지하도록 하는 기술입니다. agentmemory, mem0, LangChain의 ConversationBufferMemory 같은 도구들이 있습니다. LLM Wiki를 "공유 가능한 영구 메모리"로 본다면, 이 분야와 본질적으로 같은 문제를 다루고 있습니다.
Personal Knowledge Management (PKM) 도구들
이 분야의 주요 도구들도 알아두면 좋습니다. Obsidian은 로컬 markdown 기반의 무료 도구로 LLM Wiki의 표준 인터페이스가 됐습니다. Logseq는 outliner 스타일의 오픈소스 대안입니다. Tana는 supertag 시스템으로 구조화된 데이터를 다루는 데 강합니다. Heptabase는 시각적 화이트보드 방식으로 공간적 사고를 지원합니다. Notion은 협업과 친숙한 UI에 강점이 있고 AI 기능도 빠르게 추가하고 있습니다.
새롭게 등장한 LLM Wiki 구현체들
Karpathy gist가 공개된 후 한 달 만에 다양한 구현체가 등장했습니다. OmegaWiki는 23개의 Claude Code skill로 연구의 전체 라이프사이클을 커버하며 별 440개를 받았습니다. Kompl은 흩어진 링크와 북마크를 살아있는 위키로 컴파일하는 도구입니다. claude-obsidian은 10개의 skill과 hot cache 시스템을 갖춘 가장 완성도 높은 Obsidian 통합 구현체 중 하나입니다. agentmemory 기반의 LLM Wiki v2는 lifecycle 관리, BM25+벡터+그래프의 triple retrieval 등 production 급 기능을 추가했습니다.
9. LLM Wiki vs RAG: 한 눈에 비교
항목 RAG LLM Wiki
| 처리 시점 | 쿼리 시점 | 자료 수집 시점 |
| 상태 | Stateless | Stateful |
| 누적성 | 누적 안됨 | 사용할수록 똑똑해짐 |
| 모순 처리 | 어려움 | 자동 표시 |
| 종합 질문 | 약함 | 강함 |
| 셋업 난이도 | 낮음 | 중간 |
| 인간 가독성 | 낮음 (벡터 DB) | 높음 (markdown) |
| 의존성 | 벡터 DB 필요 | markdown 파일만 |
| 도구 종속성 | 보통 높음 | 낮음 (도구 교체 자유) |
10. 누구에게 좋은가?
LLM Wiki가 특히 빛을 발하는 사람들이 있습니다.
연구자와 대학원생: 매주 수십 편의 논문을 읽지만 시간이 지나면 무엇을 읽었는지 기억나지 않는다면, LLM Wiki는 게임체인저가 됩니다.
컨설턴트와 애널리스트: 다양한 산업과 회사에 대한 정보가 누적되어 시간이 지날수록 통찰의 깊이가 깊어집니다.
작가와 콘텐츠 크리에이터: 모든 읽은 자료가 다음 글의 재료가 됩니다. 한 substack 작가는 모든 자신의 글을 LLM Wiki에 넣어 56개의 상호 연결된 페이지를 만들고, 이를 새 글의 토대로 사용한다고 합니다.
평생 학습자: 책, 팟캐스트, 강의, 블로그를 닥치는 대로 흡수하지만 머릿속에 정리되지 않는 분들에게 안성맞춤입니다.
반면 다음 경우에는 신중히 고려해야 합니다. 단순 검색만 필요한 경우, 자료를 자주 추가하지 않는 경우, 마크다운과 터미널 사용에 거부감이 있는 경우에는 ChatGPT나 NotebookLM 같은 단순한 RAG 도구가 더 나을 수 있습니다.
11. 시작하기 위한 자료 모음
가장 먼저 봐야 할 것은 Karpathy의 원본 gist입니다. 단 한 페이지로 모든 철학이 담겨 있습니다.
확장된 production-grade 패턴이 궁금하다면 LLM Wiki v2 (rohitg00 fork)를 참고하세요.
본격적인 구현체로 OmegaWiki와 claude-obsidian을 살펴보면 실제로 어떻게 동작하는지 감이 옵니다.
AI 도구 선택이 고민되면 Artificial Analysis - Coding Agents Comparison에서 최신 비교표를 확인할 수 있습니다.
마무리: "당신의 역할이 바뀐다"
Karpathy의 통찰의 핵심은 단순합니다. 지식 베이스 유지에서 가장 어려운 부분은 읽기나 사고가 아니라 부기(bookkeeping)다. 교차 참조 업데이트, 요약 갱신, 새 정보로 인한 모순 표시, 수십 페이지에 걸친 일관성 유지. 인간이 늘 포기해온 일이고, LLM이 가장 잘하는 일입니다.
LLM Wiki의 핵심은 세 기둥의 협주입니다. Wiki는 누적되는 자산을 만들고, AI는 그 자산을 만들고 답하고 정리하며, Obsidian은 사람이 그 자산을 보고 쓰게 해줍니다. 셋이 함께일 때 비로소 시간이 지날수록 똑똑해지는 시스템이 완성됩니다.
그리고 이 시스템은 누구에게나 열려 있습니다. Claude Code의 유료 구독자도, Gemini CLI 무료 사용자도, Ollama로 로컬 모델을 돌리는 프라이버시 옹호자도 똑같이 이 패턴을 활용할 수 있습니다. 위키는 그냥 markdown 폴더이고, AI는 갈아끼울 수 있습니다.
당신이 해야 할 일은 단 세 가지입니다. 자료를 큐레이션하고, 분석을 지시하고, 좋은 질문을 던지세요. 나머지는 LLM이 다 합니다.
오늘 vault 하나 만들고, gist 하나 던지고, 첫 자료 하나 ingest 해보세요. 그게 시작입니다.
'AI 관련 자료' 카테고리의 다른 글
| 클로드 디자인 결과문 13분만에 안드로이드 앱 코드 생성 및 앱 실행까지 (0) | 2026.05.16 |
|---|---|
| 클로드 디자인 결과물 클로드 코드로 작업하기 - 간단 설명 (0) | 2026.05.12 |
| 디자인 못하는 개발자가 Claude Design으로 운동 앱 UI 만들어본 솔직 후기 (0) | 2026.05.09 |
| Claude Cowork 시작하기: 개발자를 위한 입문 가이드 (0) | 2026.05.09 |
| AI 에이전트 활용법 7가지 총정리 (2026년 최신판) (0) | 2026.05.07 |



